
Wenn Ihr Vertragsbestand wächst, verspricht „KI“ oft das Unmögliche: alles lesen, jede Klausel extrahieren, jede Frage sofort beantworten. Die Realität ist zugleich bodenständiger und wirkungsvoller: Moderne Systeme machen Verträge durchsuchbar, strukturiert und alarmfähig – vorausgesetzt, Sie kombinieren die richtigen Modelle mit passenden Workflows, Datenschutzkontrollen und Erfolgsmetriken. Dieser Artikel trennt Signal von Rauschen und liefert einen konkreten Zwei-Wochen-POC-Plan, mit dem Sie Anbieter belastbar vergleichen.
Ein kurzes Glossar (ohne Buzzword-Nebel)
OCR (Optical Character Recognition).
Verwandelt Pixel in Text. Qualität hängt von Scanauflösung, Fonts, Sprachpaketen und Artefakten (Stempel, Unterschriften, Redlines) ab. Schlechte OCR = schlechte Grundlage.
NLP (klassische Sprachverarbeitung).
Regelbasierte/statistische Verfahren (Regex, CRF, SVM) für Entitäten, Daten, Parteien, Klausel-Header. Schnell und vorhersehbar bei engen Aufgaben; brüchig, wenn Verträge stark abweichen.
LLM (Large Language Model).
Neuronale Modelle zum Verstehen/Generieren von Sprache. Stark bei Klauselklassifikation, Feldextraktion in unaufgeräumten Layouts und Zusammenfassungen. Braucht Leitplanken, Evaluation und Datenschutz.
RAG (Retrieval-Augmented Generation).
Statt „auswendig lernen“: Relevante Seiten/Klauseln zitieren und darauf basierend antworten. Reduziert Halluzinationen und liefert Anker für Reviewer.
HITL (Human-in-the-Loop).
Menschen prüfen Stichproben (oder 100 %) der Vorhersagen, korrigieren Fehler und speisen Verbesserungen zurück. Das ist Qualitätskontrolle und Risikomanagement – kein KI-Scheitern, sondern Designprinzip.
Was KI für Verträge heute kann – und was (noch) schwierig ist
Zuverlässig möglich
-
Erkennen gängiger Klauselfamilien (Vertraulichkeit, Rechtswahl, Abtretung, Verlängerungen).
-
Extrahieren häufiger Felder (Wirksamkeitsdatum, Laufzeit, Kündigungsfrist, Parteien, Unterschriften).
-
Normalisieren von Werten („thirty (30) days“ → 30 Tage); Mapping in strukturierte Felder.
-
Zusammenfassen von Risiken/Pflichten mit Quellenstellen.
-
Erinnerungen/Aufgaben anhand extrahierter Daten auslösen.
Variabel oder schwierig
-
Komplex verhandelte Sprache, die Pflichten über mehrere Abschnitte verteilt (z. B. CPI-Formeln in Anhängen).
-
Schwache Scans/Faxe, schwere Track-Changes/Watermarks.
-
Mehrsprachige Pakete auf derselben Seite; seltene Jurisdiktionen/Termini.
-
Tabellen als Bilder, rotiert oder über Seiten getrennt.
Erfolg entsteht, wenn Sie für die schwierigen Teile designen: bessere OCR-Pipelines, saubere Evaluation, HITL-Queues – so bleibt Genauigkeit hoch und Vertrauen intakt.
Evaluationskriterien, die Erfolg wirklich vorhersagen
1) Verteidigbare Genauigkeit: Precision, Recall und Datensatz
Verlangen Sie Precision/Recall/F1 auf Ihren Dokumenten, nicht auf Marketing-Samples. Definieren Sie die Wahrheitseinheit (Feld, Klausel, Dokument) und bestehen Sie auf:
-
Stratifiziertem Testset: Legacy-Scans, moderne PDFs, Sprachenmix, verhandelte vs. Template-Verträge.
-
Konfusionsanalyse (was wurde als was fehlklassifiziert) und Fehler-Taxonomie (Datumsfehler, Einheitennormierung, Klausel verpasst, falsche Seite).
-
Inter-Rater-Agreement zwischen zwei menschlichen Annotatoren – sonst jagen Sie „Modellfehlern“ hinterher, die in Wahrheit Uneinigkeit der Reviewer sind.
Hinweis: Messen Sie Recall (fand das System jede Verlängerungsklausel?) und Precision (sind die Funde korrekt?). Ein verpasster Auto-Renewal ist meist schlimmer als zwei False Positives.
2) Abdeckung & Robustheit
-
Taxonomie-Fit. Können Sie eigene Felder/Klauseln definieren (z. B. „IP-Freistellungskappung“, „Most Favored Customer“)?
-
Layout-Varianz. Performance bei ungewöhnlichen Headern, dichten Anlagen, eingebetteten Bildern.
-
Redlines/Track-Changes. Ignoriert das System Markup – oder „liest“ es gelöschte Texte als gültig?
3) Erklärbarkeit & Nachvollziehbarkeit
-
Span-Highlights für jedes extrahierte Feld (genaue Wortstelle).
-
Konfidenzwerte, die mit realer Korrektheit korrelieren (niedrig → automatische HITL-Zuweisung).
-
Versionierte Modelle & unveränderliche Logs: Jede Änderung (Modellupdate oder Mensch) ist belegt.
4) Sicherheit & Datenschutz als Default
-
Datenresidenz (z. B. EU/Deutschland) und klare Subprozessor-Offenlegung.
-
Verschlüsselung (Übertragung/Ruhe), Schlüsselmanagement, Least-Privilege Zugriff.
-
RBAC + SSO/MFA gegen Oversharing.
-
PII-Handling: Maskierung/Redaktion; Verarbeitung ohne Vendor-Retention.
-
Logging & Retention: Exportierbar, manipulationssicher, konfigurierbare Aufbewahrung/Löschung.
5) Workflow-Fit & Integrationen
-
Queue-Design: Sortieren nach Risiko, Konfidenz, Fälligkeit.
-
E-Sign/DMS/CRM/ERP-Konnektoren: Metadaten aus CRM ziehen; Pflichten als Aufgaben zurückspielen; Executed Copies mit richtigen Rechten ablegen.
-
APIs/Webhooks für Synchronisierung und Automatisierung.
6) Kostenmodell & TCO
-
Preismechanik: pro Dokument/Seite/User/Compute – was skaliert mit Volumen?
-
Verdeckte Kosten: Annotation, Re-Processing schlechter Scans, manuelle QC für Low-Confidence.
-
Werthebel: Zeitersparnis, vermiedene Strafzahlungen, gefangene Renewals – bauen Sie eine konservative Business-Case-Rechnung.
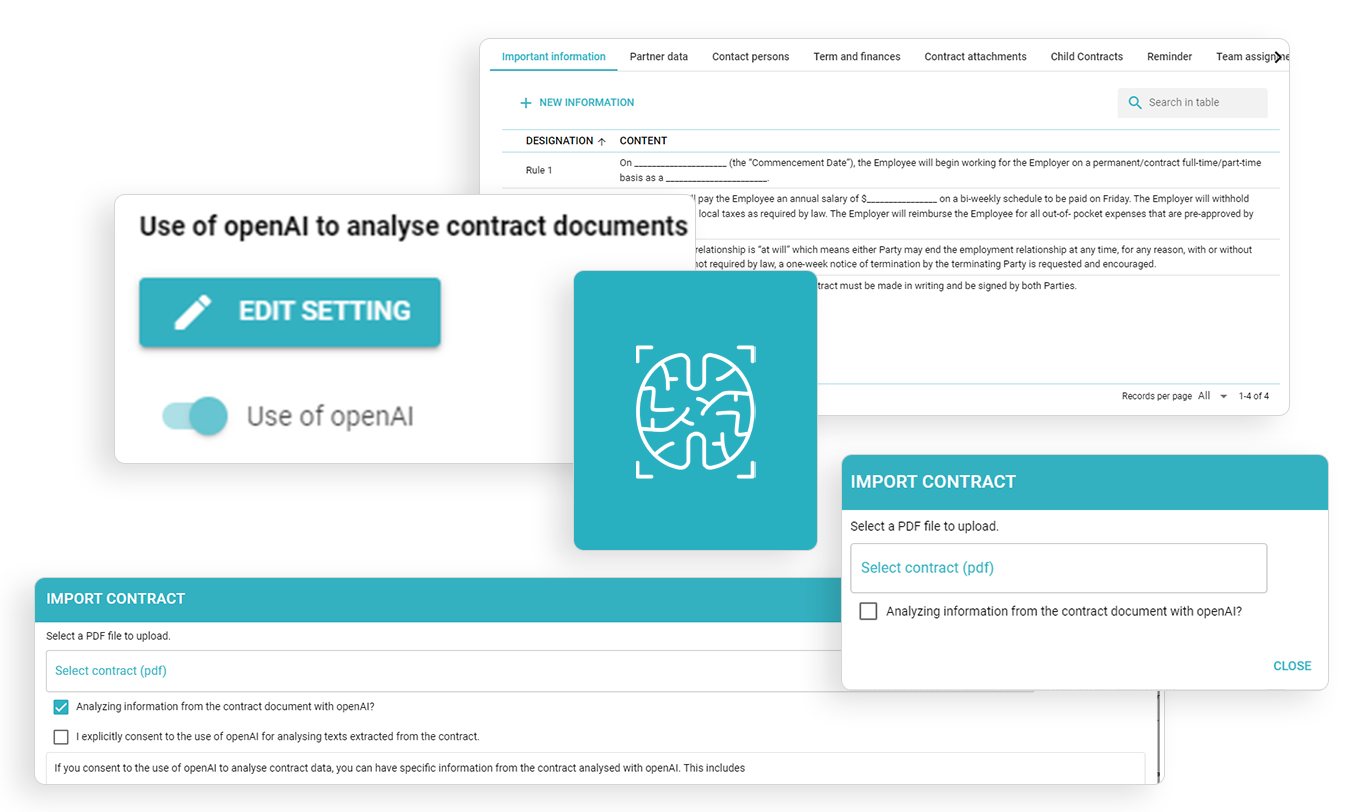
Scan with AI
Scan with AI and place common details automatically.
Available for all versions and possible to disable.
Der 2-Wochen-POC-Plan (Ihre Checkliste)
Ziel: Go/No-Go anhand Ihrer Verträge – mit Zahlen für Legal, Finance und IT.
Tag 0: Erfolg definieren
-
Use-Cases: z. B. Auto-Renewals/Kündigungsfristen erkennen; CPI-Erhöhungen; Rechtswahl klassifizieren.
-
Abnahmekriterien: z. B. ≥ 92 % Recall und ≥ 90 % Precision bei Renewals/Fristen; ≥ 80 % weniger Suchzeit.
-
Constraints: Datenresidenz? PII-Maskierung? Reviewer-Kapazität?
Tage 1–3: Evaluationspaket bauen
-
150–250 Dokumente repräsentativ (10–20 % schlechte Scans; 20–30 % verhandelt; 10–20 % Nicht-Deutsch falls relevant).
-
Blinde Ground-Truth durch zwei Reviewer; Konflikte schlichten.
-
Red-Team-Set (10–20 Docs) mit tricky Layouts und Edge-Cases.
Tage 4–7: Pipelines laufen lassen
-
Vendor verarbeitet das Paket mit Standards; kein Sondertuning außer Sprach/OCR-Packs.
-
Sie messen pro Feld/Klausel Precision/Recall/F1; füllen die Fehler-Taxonomie.
Tage 8–10: Human-in-the-Loop testen
-
Low-Confidence Items → Reviewer; messen Time-to-Correct und Post-Review-Genauigkeit.
-
Sicherstellen, dass Korrekturen auditiert und wiederverwendet werden (Active Learning/Regelupdate).
Tage 11–12: Security & Privacy verifizieren
-
Datenflüsse, Logs, Subprozessoren, Residenz prüfen.
-
RBAC, SSO/MFA, PII-Maskierung, Retention/Löschung bestätigen.
-
SIEM-taugliche Logs für einen Beispiel-Dokumentenlauf exportieren.
Tage 13–14: Executive Readout
-
Metriken, Risiken, Kosten: Wo ist das Modell verlässlich? Wo bleibt HITL Pflicht? Welcher ROI (Zeit, Strafvermeidung, Renewal-Capture)?
-
Go/No-Go + Rollout-Plan (zuerst Templates, Legacy-Import später).
Lieferobjekte, auf die Sie bestehen sollten
-
Konfusionsmatrix, Precision/Recall/F1 je Feld/Klausel.
-
Fehler-Taxonomie mit Abhilfen.
-
Beispiel-Span-Highlights & Konfidenz-Verteilung.
-
Sicherheitsarchitektur + DPA/Subprozessor-Liste.
-
TCO-Modell mit Volumenannahmen.
Red Flags & Versprechen, die Vorsicht verdienen
-
„100 % Genauigkeit.“ Gibt es nicht. Fordern Sie Rohzahlen auf Ihrem Datensatz.
-
„Kein Training, keine Reviews nötig.“ Sie brauchen Policy-Tuning und HITL für Edge-Cases.
-
„Laden Sie erst mal alles hoch.“ Starten Sie mit repräsentativer Stichprobe – sonst entsteht eine digitale Rumpelkammer.
-
Opaque Modelle. Ohne Span-Belege, Modell-Versionierung, Change-Logs wird Audit schmerzhaft.
-
Vendor-Retention by Default. Verbesserungen sollten nicht das Behalten Ihrer Daten voraussetzen – außer mit expliziter Opt-in-Regelung und Schutz.
Erklärbarkeit designen (damit Legal die Ausgaben vertraut)
Rechtsteams wollen Belege, keine Mystik:
-
Zitate überall. Jede Zusammenfassung zeigt die exakte Klauselstelle.
-
Konfidenz-Schwellen. Hochkritische Felder (z. B. Kündigungsfrist) erst ab Mindestkonfidenz automatisch übernehmen; Rest → Review.
-
Quellen-Disziplin. Die ausgeführte PDF bleibt Kanon; strukturierte Felder sind Index, nicht Ersatz.
-
Change-Control. Jede Änderung (neues Modell, menschliche Korrektur) mit Wer/Was/Wann/Warum.
So wechseln Sie von „Die KI sagt“ zu „Hier ist die Klausel, hier der Prüfer, hier der Zeitpunkt“.
Wo KI jetzt den größten Nutzen stiftet
-
Vigilanz bei Renewals & Fristen. Kündigungsfenster/Auto-Renewals extrahieren; Owner zuweisen; vor Frist eskalieren.
-
Normalisierung kommerzieller Konditionen. Zahlungs-/Preisformeln, CPI, Rabatte, SLAs vereinheitlichen.
-
Risikotriage. Auffällige Haftungskappen, Freistellungen, MFN, Rechtswahl/-Gerichtsstand markieren.
-
Legacy unlocken. Akten-PDFs in einen abfragbaren Korpus verwandeln – Antworten in Minuten statt Tagen.
Alle vier liefern messbare Effekte (vermeidene Strafen, gesicherter Umsatz, Zeitersparnis) und bilden das Rückgrat eines belastbaren ROI-Cases.
Der contractSILO-Ansatz (kurz)
contractSILO kombiniert OCR + LLM + RAG mit HITL-Queues, Span-Zitaten und rollenbasierter Zugriffskontrolle. Hosting in der EU (inkl. Deutschland), SSO/MFA, audit-fähige Logs und Integrationen zu E-Sign sowie gängigen CRM/ERP-Systemen sind verfügbar; APIs/Webhooks treiben Folgeaufgaben und Alerts an. Ergebnis: vertrauenswürdige, nachweisbare Vertragsdaten – ohne Datenschutz zu opfern.
KI versteht nicht jede Klausel jedes Vertrags magisch. Mit disziplinierter Evaluation, erklärbaren Vorhersagen und menschlicher Kontrolle, wo es zählt, verwandeln Sie statische PDFs in ein lebendes System von Pflichten, Terminen und Risiken – inkl. Alerts und Dashboards, nach denen das Business handeln kann. Folgen Sie dem 2-Wochen-POC, verlangen Sie verteidigbare Metriken – dann wissen Sie, wo KI sich auszahlt und wo Menschen am Steuer bleiben.
1) Wie viel Trainingsmaterial brauchen wir für Nischenklauseln?
Überraschend wenig, wenn der Anbieter Custom-Regeln und Active Learning unterstützt. Starten Sie mit 30–50 gut annotierten Beispielen pro Klauseltyp über diverse Layouts. Qualität & Varianz schlagen rohe Menge; erweitern Sie gezielt um Fehlschlag-Beispiele.
2) Was ist der Unterschied zwischen Precision und Recall – und was zählt mehr?
Precision misst Korrektheit der Treffer (weniger False Positives). Recall misst, wie viele aller relevanten Fälle gefunden wurden (weniger Misses). Bei Kündigungsfristen wiegt Recall oft schwerer – lieber zwei False Positives prüfen als eine echte Frist verpassen. Tracken Sie beide plus F1.
3) Können wir mit synthetischen Dokumenten testen?
Ja, zum Stresstest spezieller Muster (verschachtelte Tabellen, exotische Datumsformate). Sie ersetzen aber keine repräsentative Stichprobe Ihrer echten Verträge (Scans, Verhandlungen, Mehrsprachigkeit).
4) Wie gehen wir mit mehrsprachigen Verträgen um?
Pipeline mit sprachbewusster OCR und passenden Modellen. Pro Sprache evaluieren, nicht nur aggregiert. Bei kritischen Feldern zunächst niedrigere Konfidenzschwellen → HITL, bis genügend Beispiele vorliegen.
5) RAG oder Fine-Tuning – wann nutze ich was?
RAG für Antworten, die im Original belegt sein müssen (meistens). Fine-Tuning für repetitive Klassifikation/Extraktion mit stabiler Taxonomie und hohem Durchsatz. Viele Teams nutzen beides: RAG für erklärbares Q&A, getunte Extraktoren für Volumenfelder.
Dieser Artikel dient der Information und ist keine Rechtsberatung. Legen Sie Anforderungen mit Rechts- und Security-Teams passend zu Branche/Jurisdiktion fest.
Das könnte Ihnen auch gefallen

